



미국 주식 데이터 수집 #10 미국 주식 장기간 실적 데이터(stockrow.com)





안녕하세요, 오랜만에 데이터 수집 관련 포스팅으로 돌아왔습니다. 미국 주식 데이터 수집을 시작한지도 벌써 5개월이 되었네요. 조금씩 지표들을 추가하다보니 어느덧 꽤나 많은 지표들을 관리하게 되었습니다. 지표의 수만큼 중요한 것이 데이터의 정합성일텐데요. 실제로 퀀트 투자를 하기 위해 데이터를 쓰려고 하다보니 막상 필요한 데이터가 없는 경우가 많았습니다. 지금까지 주로 Yahoo Finance의 데이터를 이용하였는데, 이유는 알 수 없지만 데이터가 없는 경우가 많았습니다. 데이터의 중요성을 뼈저리게 느끼고 있습니다😉
예를 들어서 한 종목을 살펴보겠습니다. 아래 캡처 화면은 Yahoo Finance에서 Airbnb(ABNB)를 검색한 화면입니다. 유명하고 큰 기업임에도 불구하고 순이익 증가율(YoY)에 대한 정보가 N/A로 표기되고 있습니다.
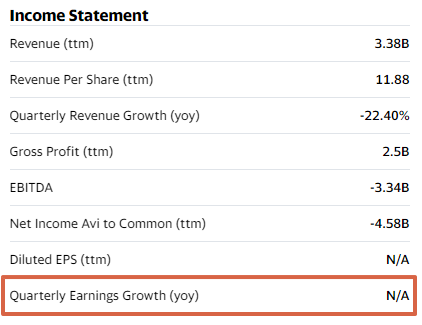
또한 직접 계산을 하려고 해도 대부분의 종목들의 최근 4개 분기 실적만 공개하고 있어서 분기 실적 YoY를 계산할 수는 없었습니다. Airbnb 같은 경우에는 작년 4분기 실적만 표기가 되고 있습니다. 실적이 없는 것도 아닐텐데 왜 그런지 잘 모르겠습니다😥

1.필요한 데이터 찾기
그래서 실적 데이터의 원천 소스를 추가로 구해보기로 하였습니다. 네이버에서도 해외 주식에 대한 정보가 있고, 크롤링 자체가 매우 쉽기 때문에 괜찮은 소스이기는 합니다. 하지만 없는 종목도 있고, 뜬금없이 실적이 다른 경우도 있었습니다. 그렇게 다른 사이트를 전전하다가 stockrow.com에서 장기간 실적 정보를 제공하고 있다는 것을 알게 되었습니다.

이렇게까지 장기간 데이터가 필요는 없지만, 그래도 원하는 데이터는 충분히 구할 수 있어서 좋았습니다. 애플(AAPL)의 경우 무려 2011년부터 분기 실적 데이터를 제공하고 있네요. 나중에 미국 주식 백테스트 기능을 만들 때 활용해보면 좋을 것 같습니다. 언젠가는 할 수 있겠죠😂
2. 데이터 크롤링 준비하기
아래는 일종의 준비 과정의 소스코드라고 할 수 있습니다. 필요한 라이브러리를 import하고 DB의 접속하는 커서를 생성하고 하는 등의 작업이죠.
2.1. 필요 라이브러리 import
import requests
import pandas as pd
import pymysql
import datetime
from dateutil.relativedelta import relativedelta
2.2. 로컬 DB 접속
def connect_db():
return pymysql.connect(host='localhost', user='DB ID', password='DB PW', db='DB NAME', charset='utf8')생성한 로컬 DB에 연결하는 함수입니다. 접속을 할 때마다 모든 정보를 입력하기 귀찮으니 함수로 만들어서 쓰는 것이죠. 여기서 DB ID, DB PW, DB NAME은 각자 자신이 생성한 DB의 정보를 기입하면 됩니다😉
2.3. 종목(티커) 리스트 가져오기
conn = connect_db()
curs = conn.cursor()
sql = "SELECT DISTINCT STOCK_CODE FROM USA_STOCK_INFO"
curs.execute(sql)
stock_list = [item[0] for item in curs.fetchall()]
conn.commit()
conn.close()
len(stock_list)저는 평소 제가 미국 주식 데이터를 수집하던 테이블에 그대로 데이터를 축적할 생각입니다. 그래서 대상이 되는 종목(티커)리스트를 조회하고, 해당 종목들의 정보를 가져올 생각입니다. 위 코드를 실행하면 stock_list라는 변수에 종목(티커) 리스트가 담기게 됩니다.
이제 필요한 사전 준비 코드는 모두 실행되었습니다. 본격적으로 stockrow.com에서 장기간 실적 데이터를 추출하는 함수를 알아보겠습니다. 상세 코드는 아래를 참조해주세요.
3. 장기간 실적 데이터 추출
제가 필요한 데이터는 분기 실적의 YoY를 계산하기 위한 최근 5개 분기의 실적입니다. 최근 5개 분기의 데이터를 수집하는 소스 코드입니다. stockrow.com 사이트에서 실적 데이터를 다운받고 해당 엑셀 파일을 읽어서 DataFrame으로 만들고 전처리하는 과정을 거치는 소스입니다. 보시고 내용이 이해 안 되시거나, 궁금한 점이 있으신 분은 말씀해주세요~
# 파일 다운로드 함수
file_path = "./ASSETS/"
def download(url, file_name = None):
if not file_name:
file_name = url.split('/')[-1]
with open(file_path+file_name, "wb") as file:
response = requests.get(url)
if response.status_code == 200:
file.write(response.content)
return True
return False# 실적 정보 다운로드 함수
def download_data(ticker):
income_url = "https://stockrow.com/api/companies/{ticker}/financials.xlsx?dimension=Q§ion=Income%20Statement&sort=desc"
# Ticker 실적 정보 다운로드
income_down = download(income_url.format(ticker=ticker), "{ticker}_INCOME.xlsx".format(ticker=ticker))
if income_down == True:
return True
else:
return False# 실적 정보 가져오는 함수
def get_stock_data(ticker):
# Ticker 주식 정보 Read
df_income = pd.read_excel(file_path+"{ticker}_INCOME.xlsx".format(ticker=ticker), index_col=0).fillna(0)
df_income = df_income.T
list_isnert = []
null_value = float(0)
# 매출액 최근 5분기
if 'Revenue' in df_income.columns:
for i in range(0,5):
list_isnert.append(float(df_income.iloc[i]['Revenue']))
else :
list_isnert = list_isnert + [0,0,0,0,0]
# 영업이익 최근 5분기
if 'Operating Income' in df_income.columns:
for i in range(0,5):
list_isnert.append(float(df_income.iloc[i]['Operating Income']))
else :
list_isnert = list_isnert + [0,0,0,0,0]
# 순이익 최근 5분기
if 'Net Income Common' in df_income.columns:
for i in range(0,5):
list_isnert.append(float(df_income.iloc[i]['Net Income Common']))
else :
list_isnert = list_isnert + [0,0,0,0,0]
list_isnert = list_isnert + [str(df_income.index[0]).replace('-','')[:8], ticker]
return list_isnert
4. DB에 실적 데이터 저장
conn = connect_db()
curs = conn.cursor()
sql = """UPDATE USA_STOCK_INFO
SET SR_RE1 = %s
, SR_RE2 = %s
, SR_RE3 = %s
, SR_RE4 = %s
, SR_RE5 = %s
, SR_OI1 = %s
, SR_OI2 = %s
, SR_OI3 = %s
, SR_OI4 = %s
, SR_OI5 = %s
, SR_NI1 = %s
, SR_NI2 = %s
, SR_NI3 = %s
, SR_NI4 = %s
, SR_NI5 = %s
, SR_YMD = %s
WHERE STOCK_CODE = %s
"""
# 반복문 돌면서 INSERT
for i, ticker in enumerate(stock_list):
try:
if download_data(ticker):
stock_info = get_stock_data(ticker)
curs.execute(sql, stock_info)
conn.commit()
# else:
# print(i, ' 번 째 ', ticker, ' : NO DATA PASS')
except Exception as e:
print(i, ' 번 째 오류 발생 : ', ticker, ' 오류:', str(e))
conn.close()3번까지 정의한 함수들을 실행하면서 DB에 입력하는 소스코드입니다. 위의 소스코드에서 테이블 명(USA_STOCK_INFO)와 필드 명(SR_RE1, SR_OI1, SR_NI1 등)은 반드시 똑같이 할 필요는 없습니다. 자신이 정의하고 싶은데로 네이밍을 진행하셔도 상관이 없고, 위의 소스코드에서 맞게 변경만 해주시면 됩니다.
아래 캡처 화면을 보면 정상적으로 잘 저장이 진행된 것을 알 수 있습니다. 중간에 실적 정보가 없어서 NULL로 되어있는 티커들도 있지만, 많지 않기 때문에 실적 분석을 하기에는 충분한 것 같습니다.

지속적으로 정합성 체크를 할 예정이고, 이번주 실적 데이터부터 함께 업로드하려고 합니다. 기대해주세요!
공감과 댓글, 공유는 큰 힘이 됩니다!
도움이 되셨다면 널리널리 알려주세요😉