



실전 백테스트 - VAA 전략




안녕하세요, 게으른 퀀트입니다. 오늘은 VAA 전략의 실전 백테스트를 진행해보도록 하겠습니다. 예전에 VAA 전략에 대한 내용들을 포스팅할 때 백테스트 결과에 대해서 다루어 보았지만, 이번 포스팅에서는 코드를 중점적으로 살펴보도록 하겠습니다. VAA와 DAA 전략의 백테스트 코드만 잘 이해해도 웬만한 동적자산 배분전략의 백테스트는 구현이 가능하니 시간을 내서 실습해보시기 바랍니다😉
1.라이브러리 import 및 메타데이터 세팅
# 필요 라이브러리 import
import pandas_datareader as pdr
import pandas as pd
from datetime import datetime, timedelta
import matplotlib.pyplot as plt
import seaborn as sns
import math
import quantstats as qs
# pandas 설정 및 메타데이터 세팅
pd.options.display.float_format = '{:.4f}'.format
pd.set_option('display.max_columns', None)
start_day = datetime(2008,1,1) # 시작일
end_day = datetime(2021,4,30) # 종료일
# RU : Risky Universe
# CU : Cash Universe
# BU : Benchmark Universe
RU = ['SPY','VEA','EEM','AGG']
CU = ['LQD','SHY','IEF']
BU = ['^GSPC','^IXIC','^KS11','^KQ11'] # S&P500 지수, 나스닥 지수, 코스피 지수, 코스닥 지수크게 세 가지의 자산군으로 나누어보았습니다. Risky Universe는 흔히 공격 자산이라고 부르는 자산군이며, Cash Universe는 방어 자산에 해당합니다. 전략의 창시자인 켈러님이 논문에서 Risky, Cash Universe라고 표현해서 그대로 사용해보았습니다. Benchmark Universe는 전략의 성과를 비교해 볼 자산군입니다. 비교하고 싶은 자산군을 추종하는 ETF or 지수 그 자체로 지정하면 됩니다.
2.데이터 추출(from Yahoo Finanace)
# 데이터 추출 함수
def get_price_data(RU, CU, BU):
df_RCU = pd.DataFrame(columns=RU+CU)
df_BU = pd.DataFrame(columns=BU)
for ticker in RU + CU:
df_RCU[ticker] = pdr.get_data_yahoo(ticker, start_day - timedelta(days=365), end_day)['Adj Close']
for ticker in BU:
df_BU[ticker] = pdr.get_data_yahoo(ticker, start_day - timedelta(days=365), end_day)['Adj Close']
return df_RCU, df_BU함수의 핵심 부분만 잘 익혀놓으면, 그 외에는 필요에 따라 수정해서 사용하면 됩니다. 아래 코드 중에서 시작일보다 1년 전 데이터부터 조회하는 이유는 모멘텀 스코어를 구하기 위해서입니다. 모멘텀 스코어를 계산하기 위해서 12개월 전 주가까지 필요하기 때문이죠.
df_RCU[ticker] = pdr.get_data_yahoo(ticker, start_day - timedelta(days=365), end_day)['Adj Close']
# 각 자산 군의 데이터 추출
df_RCU, df_BU = get_price_data(RU, CU, BU)실행 결과)

2007년에는 VEA가 없었을 때라 주가가 표기되지 않았네요. VEA가 상장될 때까지는 공격 자산을 SPY, EEM, AGG로만 가져가게 되지만, 크게 상관이 없을 것 같으니 그대로 진행해보겠습니다. 혹시 정확하게 백테스트를 진행해보실 분들은 VEA가 추종하는 지수를 구해서 진행하시면 됩니다.
3.모멘텀 지수 계산
# 모멘텀 지수 계산 함수
def get_momentum(x):
temp_list = [0 for i in range(len(x.index))]
momentum = pd.Series(temp_list, index=x.index)
try:
before1 = df_RCU[x.name-timedelta(days=35):x.name-timedelta(days=30)].iloc[-1][RU+CU]
before3 = df_RCU[x.name-timedelta(days=95):x.name-timedelta(days=90)].iloc[-1][RU+CU]
before6 = df_RCU[x.name-timedelta(days=185):x.name-timedelta(days=180)].iloc[-1][RU+CU]
before12 = df_RCU[x.name-timedelta(days=370):x.name-timedelta(days=365)].iloc[-1][RU+CU]
momentum = 12 * (x / before1 - 1) + 4 * (x / before3 - 1) + 2 * (x / before6 - 1) + (x / before12 - 1)
except Exception as e:
#print("Error : ", str(e))
pass
return momentumDataFrame에서 한 컬럼(각 자산)씩 계산하는 함수입니다. 코드를 보면 그리 복잡하지는 않습니다. x는 현재의 주가이고, 모멘텀 지수를 계산할 지난 주가를 각각 before1, before3, before6, before12로 구합니다. 실제 필요한 날짜보다 약 5일정도 이전 데이터부터 조회하는 이유는 그 날짜가 휴장일일수도 있기 때문입니다. 실제로는 .iloc[-1]을 해서 가장 마지막 날의 주가만 사용되지만 오류를 방지하기 위해 넉넉히 5일치 데이터를 가져옵니다.
# 각 자산별 모멘텀 지수 계산
mom_col_list = [col+'_M' for col in df_RCU[RU+CU].columns]
df_RCU[mom_col_list] = df_RCU[RU+CU].apply(lambda x: get_momentum(x), axis=1)실행 결과)

4.백테스트 기간 데이터 추출
# 백테스트할 기간 데이터 추출
df_RCU = df_RCU[start_day:end_day]
# 매월 말일 데이터만 추출(리밸런싱에 사용)
df_RCU = df_RCU.resample(rule='M').last()모멘텀 스코어를 계산했으니, 백테스트를 진행할 구간의 데이터만 다시 뽑아냅니다. 모멘텀 스코어가 계산되지 않은 최초 1년치 데이터는 제외합니다. 그리고 월말에 리밸런싱을 진행한다고 가정하여 월말 데이터만 남깁니다.
실행 결과)
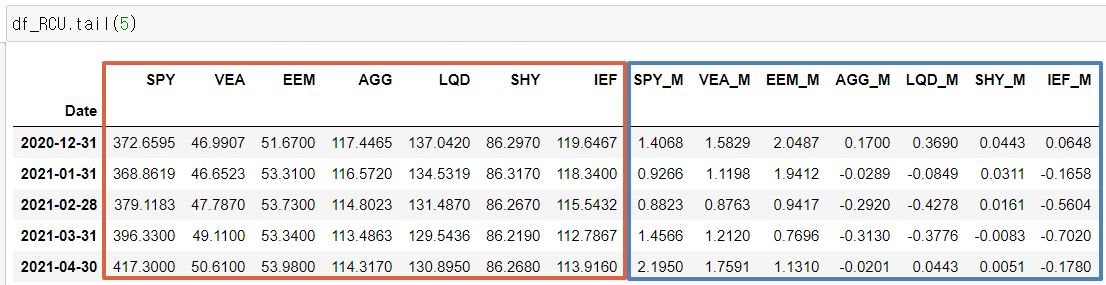
빨간색으로 표기한 영역이 해당 ETF의 주가이고, 파란색 영역이 각 ETF의 계산된 모멘텀 스코어입니다.
5.VAA 전략 기준에 맞춘 자산 선택
# VAA 전략 기준에 맞춰 자산 선택
def select_asset(x):
asset = pd.Series([0,0], index=['ASSET','PRICE'])
# 공격 자산이 모두 0이상이면, 공격 자산 중 최고 모멘텀 자산 선정
if x['SPY_M'] > 0 and x['VEA_M'] > 0 and x['EEM_M'] > 0 and x['AGG_M'] > 0:
max_momentum = max(x['SPY_M'],x['VEA_M'],x['EEM_M'],x['AGG_M'])
# 공격 자산 중 하나라도 0이하라면, 방어 자산 중 최고 모멘텀 자산 선정
else :
max_momentum = max(x['LQD_M'],x['SHY_M'],x['IEF_M'])
asset['ASSET'] = x[x == max_momentum].index[0][:3]
asset['PRICE'] = x[asset['ASSET']]
return asset자산 선택을 하는 함수입니다. 코드에 특별히 복잡한 부분은 없고, 실행 결과에 대해서 짧게 설명드리겠습니다.
# 매월 선택할 자산과 가격
df_RCU[['ASSET','PRICE']] = df_RCU.apply(lambda x: select_asset(x), axis=1)실행 결과)

공격자산 군의 모멘텀 스코어가 모두 0이상이기 때문에(빨간색 영역), 모멘텀 스코어가 가장 큰 EEM(파란색 영역)을 ASSET 이라는 필드에 따로 표기해둡니다. 수익률을 계산할 때 선택한 자산군의 수익률만 사용해야하기 때문입니다.
6.각 자산 및 VAA 전략 수익률 계산
# 각 자산별 수익률 계산
profit_col_list = [col+'_P' for col in df_RCU[RU+CU].columns]
df_RCU[profit_col_list] = df_RCU[RU+CU].pct_change()pct_change() 함수를 활용해서 전체 자산군의 지난달 대비 수익률을 계산합니다.
실행결과)

이어서 이전 달에 선택한 자산군의 이번 달의 수익률/누적수익률/로그수익률/누적로그수익률을 계산합니다.
# 매월 수익률 & 누적 수익률 계산
df_RCU['PROFIT'] = 0
df_RCU['PROFIT_ACC'] = 0
df_RCU['LOG_PROFIT'] = 0
df_RCU['LOG_PROFIT_ACC'] = 0
for i in range(len(df_RCU)):
profit = 0
log_profit = 0
if i != 0:
profit = df_RCU[df_RCU.iloc[i-1]['ASSET'] + '_P'].iloc[i]
log_profit = math.log(profit+1)
df_RCU.loc[df_RCU.index[i], 'PROFIT'] = profit
df_RCU.loc[df_RCU.index[i], 'PROFIT_ACC'] = (1+df_RCU.loc[df_RCU.index[i-1], 'PROFIT_ACC'])*(1+profit)-1
df_RCU.loc[df_RCU.index[i], 'LOG_PROFIT'] = log_profit
df_RCU.loc[df_RCU.index[i], 'LOG_PROFIT_ACC'] = df_RCU.loc[df_RCU.index[i-1], 'LOG_PROFIT_ACC'] + log_profit
# 백분율을 %로 표기
df_RCU[['PROFIT', 'PROFIT_ACC', 'LOG_PROFIT','LOG_PROFIT_ACC']] = df_RCU[['PROFIT', 'PROFIT_ACC', 'LOG_PROFIT','LOG_PROFIT_ACC']] * 100
df_RCU[profit_col_list] = df_RCU[profit_col_list] * 100 profit = df_RCU[df_RCU.iloc[i-1]['ASSET'] + '_P'].iloc[i]
지난 달에 선정한 자산군의 이번달 수익률을 VAA 전략의 이번달 수익률로 지정합니다.
실행 결과)

이전 달에 선택한 자산(빨간색 영역)의 이번달 수익률(파란색 영역)이 곧 VAA 전략 포트폴리오의 이번달 수익률(주황색 영역)이 됩니다.
7.QuantStats 리포트 결과
원래는 계산된 수익률/누적수익률/로그수익률/누적로그수익률로 그래프를 그렸지만, 이제는 QuantStats을 사용하여 리포팅 결과를 살펴보겠습니다. 훨씬 더 편리합니다😙
# QuantStats의 기본 리포트
qs.reports.basic(df_RCU['PROFIT']/100)코드 한 줄로 다양한 리포트 결과를 확인할 수 있습니다. 100으로 나눠주는 이유는 위에서 편의성을 위해서 100을 곱해줬기 때문에 다시 나누어 준 것입니다.
실행 결과)

연복리 수익률(CAGR)과 MDD 뿐만 아니라, 샤프지수나 낙폭이 지속된 최대 기간(Longest DD Days) 등 다양한 정보가 표기됩니다. 뿐만 아니라 누적 수익률과 DD 그래프의 시각화도 자동으로 구현됩니다.

공감과 댓글, 공유는 큰 힘이 됩니다!
도움이 되셨다면 널리널리 알려주세요😉